
Distributed Search in Synchronous Networks
(BFS, Bell-man Ford in Distributed Network, đọc và tóm lược từ sách Distributed Algorithms của Nancy A. Lynch)

Synchronous Network
Breadth-First Search
n: Tổng số node trong mạng
diam: Đường kính của mạng
E: số cạnh (directed Edge) trong mạngBFS tree giúp tối ưu hoá thời gian giao tiếp (communication time) từ một process tại một node phân biệt tới tất cả các process khác trong network.
Bài toán BFS và giải pháp của nó bằng cách nào đó trở nên đơn giản hơn trong trường hợp tât cả kết nối giữa các cặp node trong mạng đều là kết nối 2 chiều (bidirectional communication), nghĩa rằng network graph lúc này là vô hướng (undirected).
Problem
Ta định nghĩa một directed spanning tree của 1 directed graph G = (V,E) là một rooted tree mà bao gồm tất cả các cạnh của E, tất cả các cạnh hướng từ node cha tới node con, và nó bao gồm mọi đỉnh của G. Một directed spanning tree của G với rôt node i là một breadth-first provided mà mỗi node tại khoảng cách d từ i trong G xuất hiện tại depth d trong tree (nghĩa rằng, tại khoảng cách d từ i trong tree).
Với bài toán BFS, chúng ta giả định rằng kết nối mạng giữa các node rất ổn định và có một source node i0. Ta cần một thuật toán sẽ cho ra output là một breadth-first directed spanning tree của network graph, root tại i0.
Như thông thường, các process chỉ giao tiếp với nhau qua các cạnh. Các process được giả định rằng có UID riêng nhưng các process sẽ không biết về kích thước của mạng hoặc các thông số khác về độ rộng của mạng.
SynchBFS
Ý tưởng cơ bản của thuật toán ta cần khá giống với thuật toán BFS truyền thống. Ta gọi thuật toán này là SynchBFS.
Thuật toán SynchBFS: Từ bất kì thời điểm nào, luôn có một tập hợp các process được “đánh dấu”, bắt đầu từ process i0. Process i0 gửi đi một search message tại round 1 tới tất cả những node xung quanh nó. Tại bất kì round nào, nếu một process chưa được “đánh dấu” nhận được một search message, process đó sẽ tự đánh dấu chính nó và chọn process gửi cái search message đó đi làm node cha (parent). Sau khi mỗi một process được đánh dấu, process đó cũng sẽ tiếp tục gửi search message tới tất cả những node quanh nó.
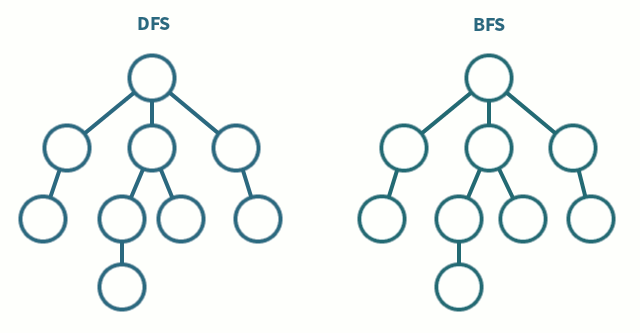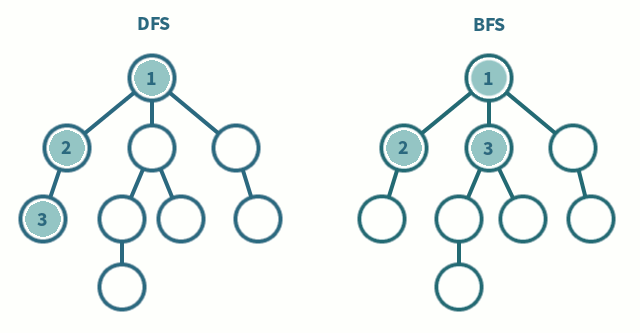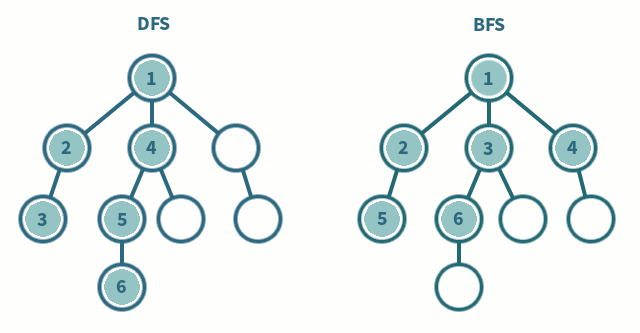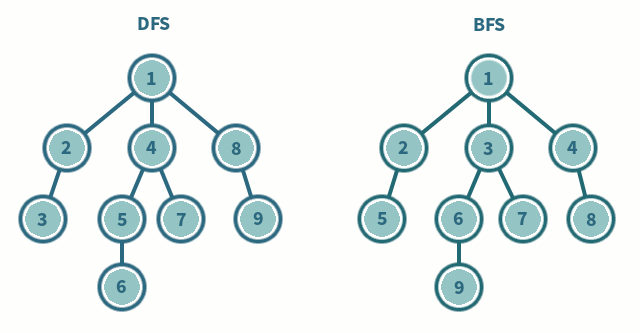
Không khó để thấy rằng giải thuật SynchBFS sẽ tạo ra một BFS tree. Để trình bày, ta có thể cung cấp một giá trị bất biến mà sau r round, mỗi process tại khoảng cách d từ i0 trong network graph, 1 <= d <= r, luôn có node cha đã được định nghĩa. Giá trị bất biến này, như thông thường, giá trị này được liên kết với số lượng round.
-
Complexity analysis: Độ phức tạp về thời gian là O(diam), cần diam round. Số tin nhắn cần gửi đi là |E|.
-
Reducing the communication complexity: Như đối với giải thuật FloodMax, việc giảm bớt số tin nhắn là khả dĩ (chưa đọc FloodMax nên chưa hiểu đoạn này)
-
Message broadcast: Giải thuật SynchBFS có thể được triển khai để broadcast tin nhắn trong mạng (vì SynchBFS tree đã bao hàm tất cả node trong mạng), lúc này thì node muốn broadcast tin nhắn sẽ là node gốc.
-
Child pointer: WIP
-
Termination: Việc gửi tin nhắn “hoàn tất” từ node lá tới node gốc có thể được thực hiện kiểu gửi từ các node con tới các node cha một cách lần lượt, quá trình này được gọi là
convergecast(truyền tin hội tụ).
Ứng dụng
Breadth-first Search là một trong những viên gạch nền móng để xây dựng distributed algorithm. Dưới đây là một số ứng dụng của giải thuật SynchBFS có thể được dùng hoặc tăng cường cho việc thực thi các thao tác khác trong distributed system.
Broadcast: Như đã được nhắc đến ở trên, một trong những ứng dụng phổ biến nhất của BFS trong Distributed System là giảm thiểu tài nguyên cho việc broadcast giữa các node với nhau. Một khi tree BFS đã được dựng lên (ánh xạ với các node trong mạng), thời gian cần thiết để broadcast một tin nhắn là O(diam).
Global computation: Một ứng dụng khác của BFS tree trong Distributed System là việc tính toán dựa trên tất cả các kết quả từ từng node. Ví dụ: Mỗi process có một số nguyên dương, và ta cần tìm tổng của các tả các số này từ toàn bộ process trong network. Nếu dùng BFS tree, vấn đề này sẽ được giải quyết đơn giản và hiệu quả như sau. Mỗi node con sẽ gửi giá trị cho node cha (parent) của nó, các node cha sẽ đợi cho tới khi các node con gửi đủ các số nguyên cho mình, cộng nó lại, rồi lại gửi cho node cha của chính nó. Giá trị cần tìm sẽ nhanh chóng được truyền tới cho root node trong BFS tree.
Electing a leader: Dùng SynchBFS, một giải thuật có thể được thiết kế để bầu ra một node leader trong network với UIDs, ngay cả khi các process trong mạng không có thông tin gì về n hay diam. Cụ thể là, tất cả các process trong mạng có thể khởi tạo các breadth-first search tree một cách song song đồng thời với nhau. Tương tự như Global computation, root node sẽ được bầu làm leader. Nếu graph undirected, thời gian cần là O(diam) và số lượng tin nhắn là O(diam * |E|).
Shortest Path
Như phần trên đã đề cập, ta dùng BFS tree để mô tả các node trong network, mục đích là tạo ra một cấu trúc thuận lợi cho việc truyền tin giao tiếp giữa các node (broadcast communication). __ Khi truyền tin, ta luôn muốn tìm đường đi ngắn nhất và có cost truyền tin thấp nhất giữa 2 node => Tìm shortest path, quy về bài toán tìm đường đi ngắn nhất trong đồ thị. Đây là một vấn đề rất quen thuộc với những người đã học qua Graph. Để giải quyết bài toán này, đến giờ có nhiều thuật toán và các biến thể, phổ biến nhất là thuật toán Dijkstra và thuật toán Bellman-Ford.
 (hình minh hoạ: Dijkstra ở trên và Bellman-Ford ở dưới)
(hình minh hoạ: Dijkstra ở trên và Bellman-Ford ở dưới)
Giải thuật Bellman-Ford ứng dụng trong mạng phân tán:
(Distributed Bellman-Ford in a message passing way  )
)
Mỗi node sẽ lấy được routing table tối ưu nhất bằng cách trao đổi routing table với các node khác. Khi trao đổi, một node gửi tin nhắn tới các node khác, tin nhắn bao gồm:
- Origin: Giá trị (UID) của node gửi tin nhắn này đi
- Routing Table: Routing Table mà node gửi đi đang có
class Node(object):
def __init__(self, name):
self.name = name
self.routing_table = {}
self.routing_table[self.name] = 0
# tin nhắn bao gồm
# - origin
# - routing_table
def process_message(message):
# Lấy cost từ node nhận tới node gửi tin nhắn
cost = self.get_cost(self.name, message['origin'])
# Duyệt qua tất cả các node trong routing table của node gửi tin nhắn
# u: là 1 node, c là cost để tới node đó trong routing table
for u, c in message['origin'].routing_table.items():
if u in self.routing_table:
# Cập nhật lại routing table theo thuật toan Bellman-Ford
# Nếu cost hiện tại tới node đó lớn hơn tổng của cost tới node phát tin nhắn và cost trong routing table, routing table của node nhận tin nhắn sẽ được cập nhật lại
if cost + c < self.routing_table[u]:
self.routing_table[u] = cost + c
else:
# Nếu node này không biết node u, nó sẽ được thêm mới vào routing table của node nhận tin nhắn
self.routing_table[u] = cost + cThuật toán khá đơn giản. Khi một node nhận được tin nhắn, nó sẽ duyệt qua tất cả các node có trong routing table của node gửi tin nhắn. Nếu cost hiện tại tới node đó lớn hơn tổng của cost tới node phát tin nhắn và cost trong routing table, routing table của node nhận tin nhắn sẽ được cập nhật lại.
Khi khởi đầu, routing table của mỗi node có giá trị như hình bên dưới:
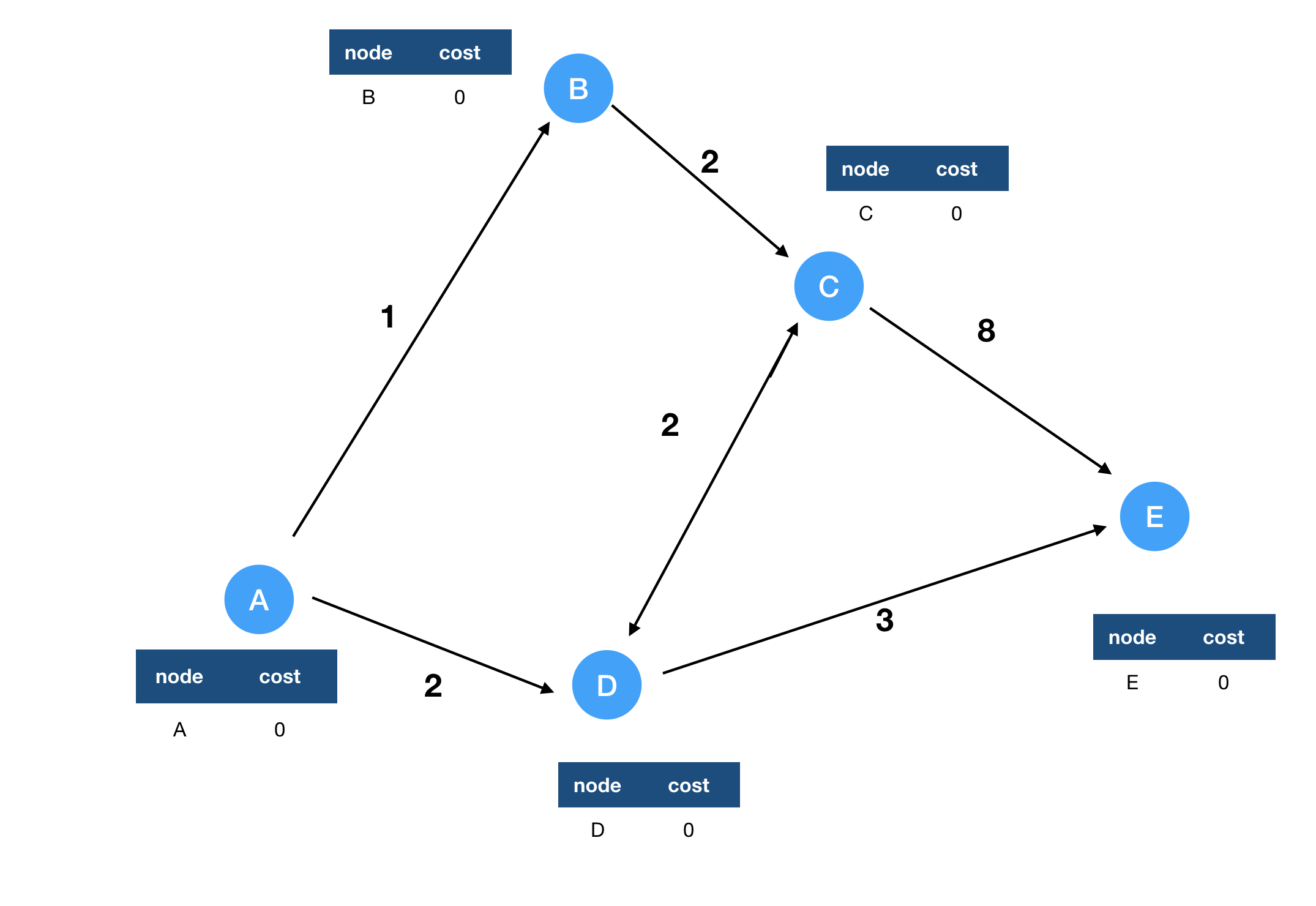
Bước tiếp theo, node A nhận tin nhắn từ node B và D kèm routing table của 2 node đó, sau khi nhận được 2 tin nhắn đó, A sẽ cập nhật lại routing table của mình lại như sau:

Cứ như vậy, các node khác cũng xử lí tin nhắn được gửi từ các node kề nó tương tự. Sau đó các routing table trên các node sẽ trông như thế này:
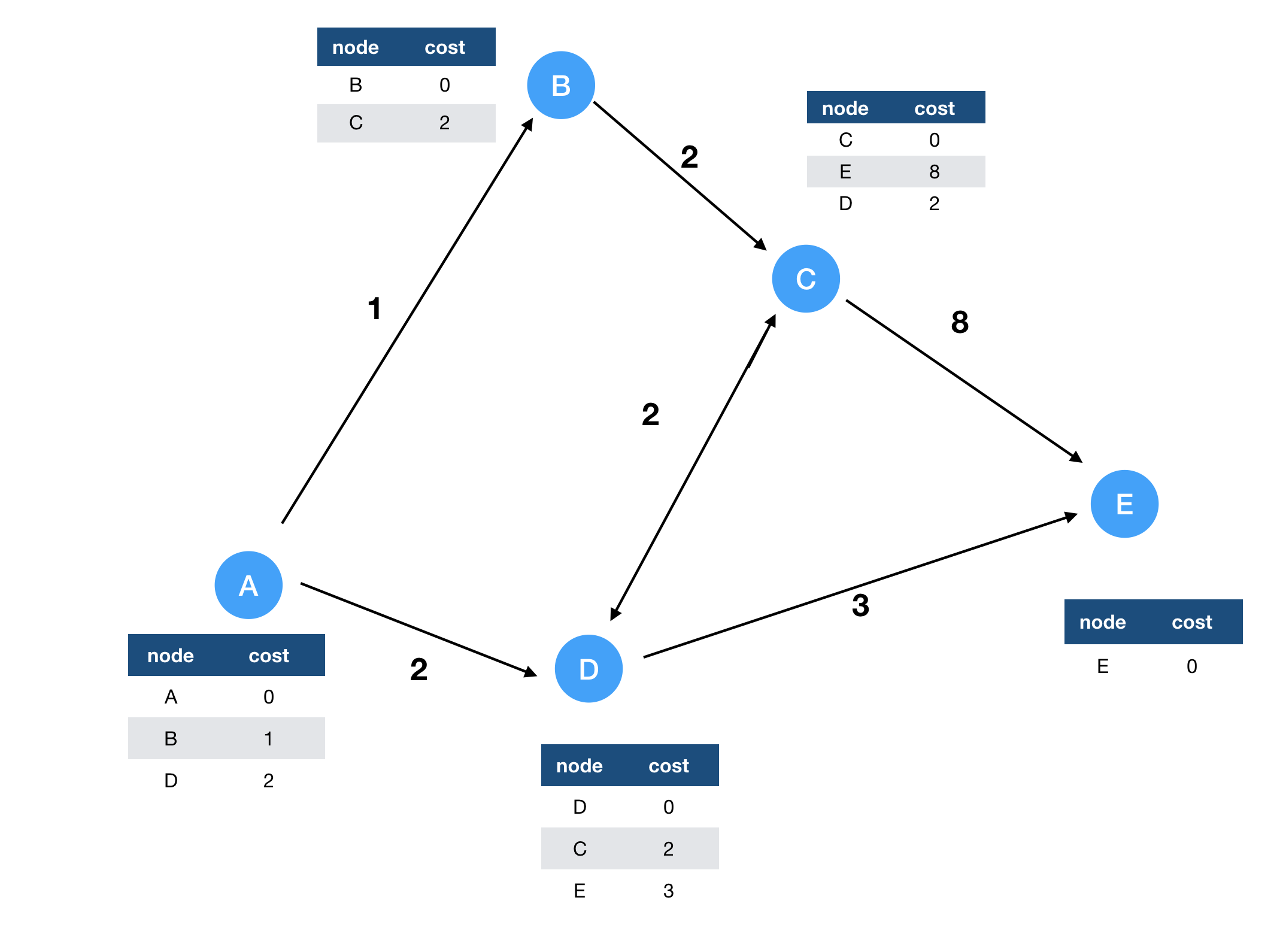
Bởi vì C không nhận được tin nhắn từ node nào, routing table của nó sẽ không được cập nhật, các node khác có liên kết vẫn nhận được routing table từ các node kề nó và liên tục cập nhật các routing table.
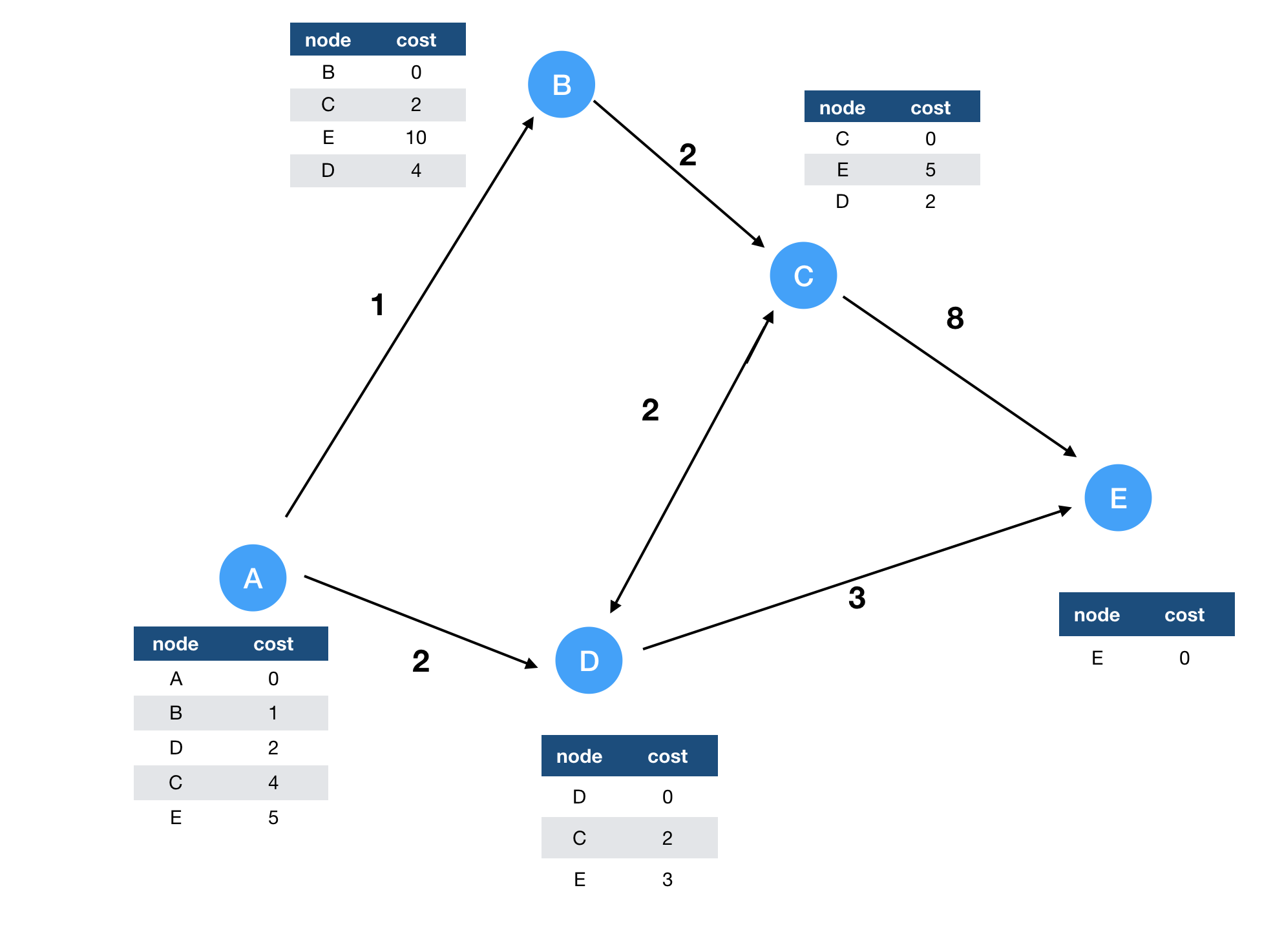
Vì C nhận được tin nhắn từ D cho việc routing tới E, C biết rằng nó có thể tới E thông qua D với cost là 5. B sau đó cũng cập nhật routing table (không tối ưu) theo C. Cứ sau mỗi round, các routing table lại được cập nhật và con số khoảng cách ngắn nhất trong các routing table càng được hội tụ về giá trị tối ưu nhất.
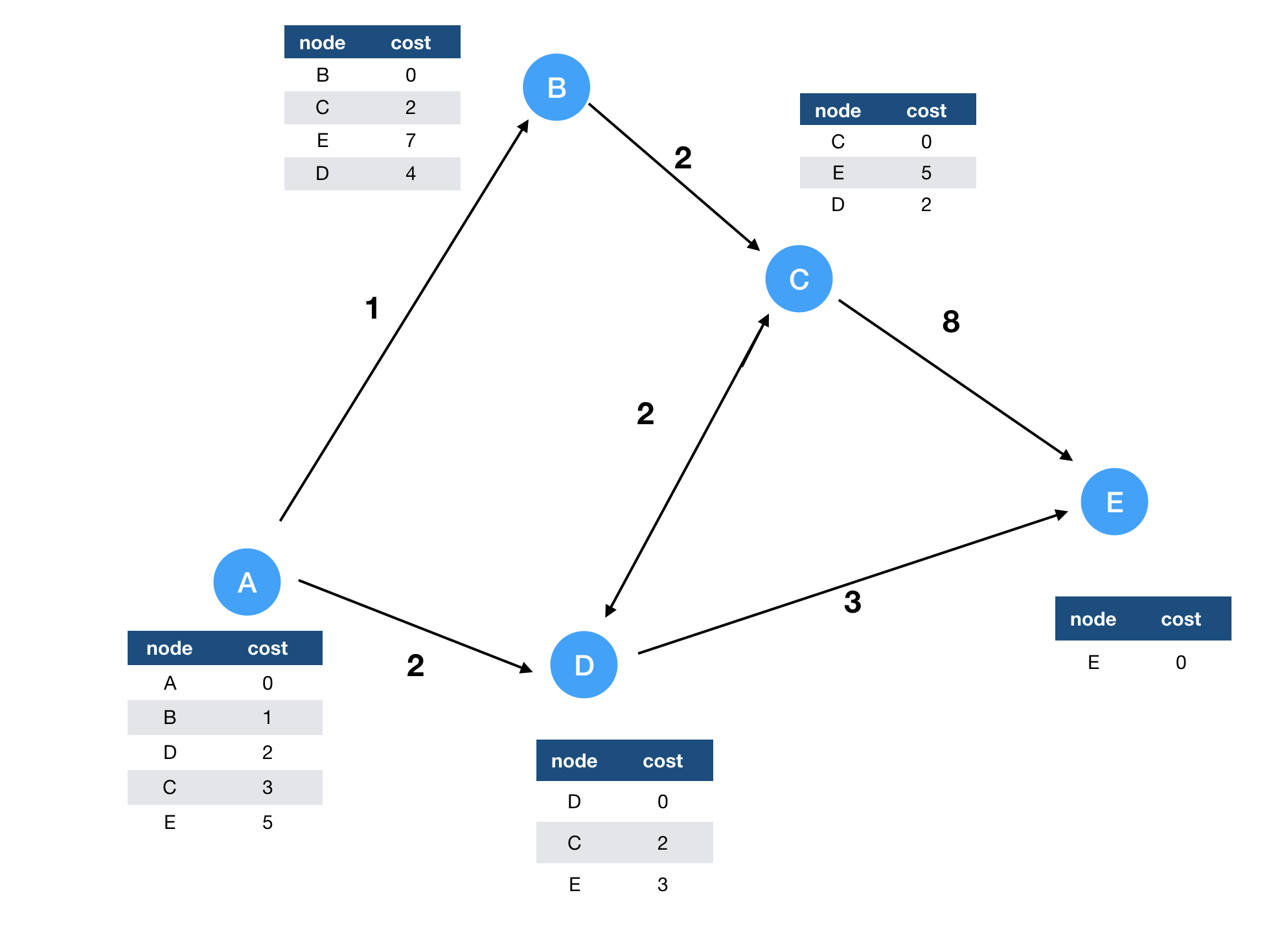
Có thể thấy, sau n - 1 round thì các giá trị trên routing table sẽ là tối ưu nhất.
*Lưu ý: Đối với giá trị cycle là số âm, thì có thể gây ra việc duyệt vô hạn lần, (1 lần duyệt 1 vòng độ dài đường duyệt sẽ giảm, càng duyệt càng giảm, vì vậy vô hạn lần).
Độ phức tạp: Độ phức tạp thời gian của giải thuật Bellman-Ford là n - 1, số tin nhắn là (n - 1) * |E|.
Asynchronous Network
WIP
